Arrow2
Arrow2 is a Rust library that implements data structures and functionality enabling interoperability with the arrow format.
The typical use-case for this library is to perform CPU and memory-intensive analytics in a format that supports heterogeneous data structures, null values, and IPC and FFI interfaces across languages.
Arrow2 is divided into 5 main parts:
- a low-level API to efficiently operate with contiguous memory regions;
- a high-level API to operate with arrow arrays;
- a metadata API to declare and operate with logical types and metadata;
- a compute API with operators to operate over arrays;
- an IO API with interfaces to read from, and write to, other formats.
Introduction
Welcome to the Arrow2 guide for the Rust programming language. This guide was created to help you become familiar with the Arrow2 crate and its functionalities.
What is Apache Arrow?
According to its website Apache Arrow is defined as:
A language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware like CPUs and GPUs. The Arrow memory format also supports zero-copy reads for lightning-fast data access without serialization overhead.
After reading the description you have probably come to the conclusion that Apache Arrow sounds great and that it will give anyone working with data enough tools to improve a data processing workflow. But that's the catch, on its own Apache Arrow is not an application or library that can be installed and used. The objective of Apache Arrow is to define a set of specifications that need to be followed by an implementation in order to allow:
- fast in-memory data access
- sharing and zero copy of data between processes
Fast in-memory data access
Apache Arrow allows fast memory access by defining its in-memory columnar format. This columnar format defines a standard and efficient in-memory representation of various datatypes, plain or nested (reference).
In other words, the Apache Arrow project has created a series of rules or specifications to define how a datatype (int, float, string, list, etc.) is stored in memory. Since the objective of the project is to store large amounts of data in memory for further manipulation or querying, it uses a columnar data definition. This means that when a dataset (data defined with several columns) is stored in memory, it no longer maintains its rows representation but it is changed to a columnar representation.
For example, lets say we have a dataset that is defined with three columns named: session_id, timestamp and source_id (image below). Traditionally, this file should be represented in memory maintaining its row representation (image below, left). This means that the fields representing a row would be kept next to each other. This makes memory management harder to achieve because there are different datatypes next to each other; in this case a long, a date and a string. Each of these datatypes will have different memory requirements (for example, 8 bytes, 16 bytes or 32 bytes).

By changing the in memory representation of the file to a columnar form (image above, right), the in-memory arrangement of the data becomes more efficient. Similar datatypes are stored next to each other, making the access and columnar querying faster to perform.
Sharing data between processes
Imagine a typical workflow for a data engineer. There is a process that is producing data that belongs to a service monitoring the performance of a sales page. This data has to be read, processed and stored. Probably the engineer would first set a script that is reading the data and storing the result in a CSV or Parquet file. Then the engineer would need to create a pipeline to read the file and transfer the data to a database. Once the data is stored some analysis is needed to be done on the data, maybe Pandas is used to read the data and extract information. Or, perhaps Spark is used to create a pipeline that reads the database in order to create a stream of data to feed a dashboard. The copy and convert process may end up looking like this:
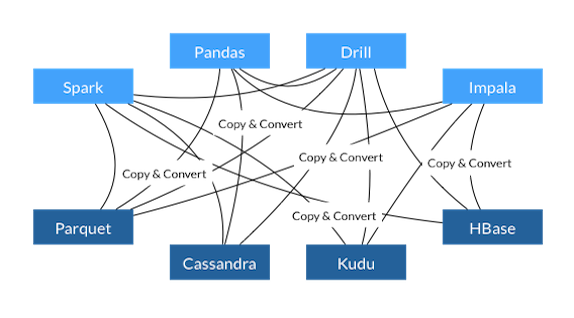
As it can be seen, the data is copied and converted several times. This happens every time a process needs to query the data.
By using a standard that all languages and processes can understand, the data doesn't need to be copied and converted. There can be a single in-memory data representation that can be used to feed all the required processes. The data sharing can be done regarding the language that is used.
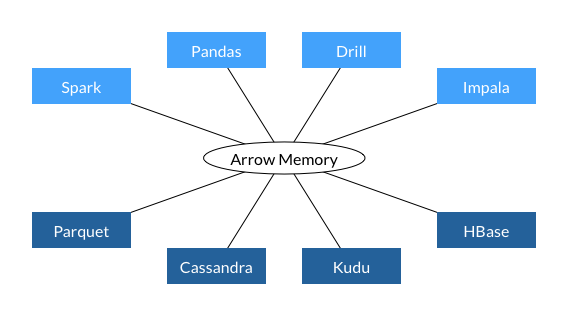
And thanks to this standardization the data can also be shared with processes that don't share the same memory. By creating a data server, packets of data with known structure (Chunk) can be sent across computers (or pods) and the receiving process doesn't need to spend time coding and decoding the data to a known format. The data is ready to be used once its being received.
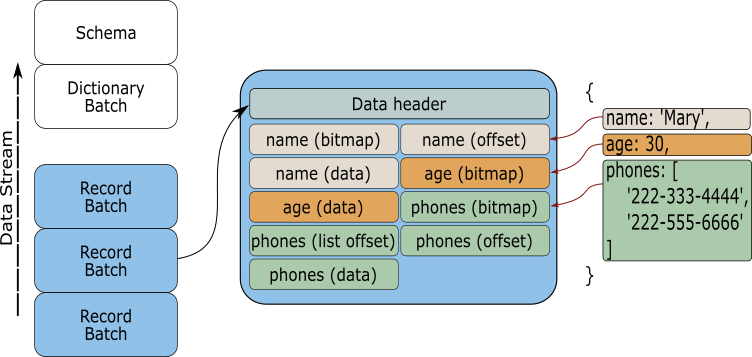
The Arrow2 crate
These and other collateral benefits can only be achieved thanks to the work done by the people collaborating in the Apache Arrow project. By looking at the project github page, there are libraries for the most common languages used today, and that includes Rust.
The Rust Arrow2 crate is a collection of structs and implementations that define all the elements required to create Arrow arrays that follow the Apache Arrow specification. In the next sections the basic blocks for working with the crate will be discussed, providing enough examples to give you familiarity to construct, share and query Arrow arrays.
Low-level API
The starting point of this crate is the idea that data is stored in memory in a specific arrangement to be interoperable with Arrow's ecosystem.
The most important design aspect of this crate is that contiguous regions are shared via an
Arc. In this context, the operation of slicing a memory region is O(1) because it
corresponds to changing an offset and length. The tradeoff is that once under
an Arc, memory regions are immutable. See note below on how to overcome this.
The second most important aspect is that Arrow has two main types of data buffers: bitmaps,
whose offsets are measured in bits, and byte types (such as i32), whose offsets are
measured in bytes. With this in mind, this crate has 2 main types of containers of
contiguous memory regions:
Buffer<T>: handle contiguous memory regions of type T whose offsets are measured in itemsBitmap: handle contiguous memory regions of bits whose offsets are measured in bits
These hold all data-related memory in this crate.
Due to their intrinsic immutability, each container has a corresponding mutable (and non-shareable) variant:
Vec<T>MutableBitmap
Let's see how these structures are used.
Create a new Buffer<u32>:
use arrow2::buffer::Buffer; fn main() { let x = vec![1u32, 2, 3]; let x: Buffer<u32> = x.into(); assert_eq!(x.as_slice(), &[1u32, 2, 3]); let x = x.slice(1, 2); // O(1) assert_eq!(x.as_slice(), &[2, 3]); }
Contrarily to Vec, Buffer (and all structs in this crate) only supports
the following physical types:
i8-i128u8-u64f32andf64arrow2::types::days_msarrow2::types::months_days_ns
This is because the arrow specification only supports the above Rust types; all other complex types supported by arrow are built on top of these types, which enables Arrow to be a highly interoperable in-memory format.
Bitmaps
Arrow's in-memory arrangement of boolean values is different from Vec<bool>. Specifically,
arrow uses individual bits to represent a boolean, as opposed to the usual byte
that bool holds.
Besides the 8x compression, this makes the validity particularly useful for
AVX512 masks.
One tradeoff is that an arrows' bitmap is not represented as a Rust slice, as Rust slices use
pointer arithmetics, whose smallest unit is a byte.
Arrow2 has two containers for bitmaps: Bitmap (immutable and sharable)
and MutableBitmap (mutable):
use arrow2::bitmap::Bitmap; fn main() { let x = Bitmap::from(&[true, false]); let iter = x.iter().map(|x| !x); let y = Bitmap::from_trusted_len_iter(iter); assert_eq!(y.get_bit(0), false); assert_eq!(y.get_bit(1), true); }
use arrow2::bitmap::MutableBitmap; fn main() { let mut x = MutableBitmap::new(); x.push(true); x.push(false); assert_eq!(x.get(1), false); x.set(1, true); assert_eq!(x.get(1), true); }
Copy on write (COW) semantics
Both Buffer and Bitmap support copy on write semantics via into_mut, that may convert
them to a Vec or MutableBitmap respectively.
This allows re-using them to e.g. perform multiple operations without allocations.
High-level API
Arrow core trait the Array, which you can think of as representing Arc<Vec<Option<T>>
with associated metadata (see metadata)).
Contrarily to Arc<Vec<Option<T>>, arrays in this crate are represented in such a way
that they can be zero-copied to any other Arrow implementation via foreign interfaces (FFI).
Probably the simplest Array in this crate is the PrimitiveArray<T>. It can be
constructed from a slice of option values,
use arrow2::array::{Array, PrimitiveArray}; fn main() { let array = PrimitiveArray::<i32>::from([Some(1), None, Some(123)]); assert_eq!(array.len(), 3) }
from a slice of values,
use arrow2::array::{Array, PrimitiveArray}; fn main() { let array = PrimitiveArray::<f32>::from_slice([1.0, 0.0, 123.0]); assert_eq!(array.len(), 3) }
or from an iterator
use arrow2::array::{Array, PrimitiveArray}; fn main() { let array: PrimitiveArray<u64> = [Some(1), None, Some(123)].iter().collect(); assert_eq!(array.len(), 3) }
A PrimitiveArray (and every Array implemented in this crate) has 3 components:
- A physical type (e.g.
i32) - A logical type (e.g.
DataType::Int32) - Data
The main differences from a Arc<Vec<Option<T>>> are:
- Its data is laid out in memory as a
Buffer<T>and anOption<Bitmap>(see [../low_level.md]) - It has an associated logical type (
DataType).
The first allows interoperability with Arrow's ecosystem and efficient SIMD operations (we will re-visit this below); the second is that it gives semantic meaning to the array. In the example
use arrow2::array::PrimitiveArray; use arrow2::datatypes::DataType; fn main() { let ints = PrimitiveArray::<i32>::from([Some(1), None]); let dates = PrimitiveArray::<i32>::from([Some(1), None]).to(DataType::Date32); }
ints and dates have the same in-memory representation but different logic
representations (e.g. dates are usually printed to users as "yyyy-mm-dd").
All physical types (e.g. i32) have a "natural" logical DataType (e.g. DataType::Int32)
which is assigned when allocating arrays from iterators, slices, etc.
use arrow2::array::{Array, Int32Array, PrimitiveArray}; use arrow2::datatypes::DataType; fn main() { let array = PrimitiveArray::<i32>::from_slice([1, 0, 123]); assert_eq!(array.data_type(), &DataType::Int32); }
they can be cheaply (O(1)) converted to via .to(DataType).
The following arrays are supported:
NullArray(just holds nulls)BooleanArray(booleans)PrimitiveArray<T>(for ints, floats)Utf8Array<i32>andUtf8Array<i64>(for strings)BinaryArray<i32>andBinaryArray<i64>(for opaque binaries)FixedSizeBinaryArray(likeBinaryArray, but fixed size)ListArray<i32>andListArray<i64>(array of arrays)FixedSizeListArray(array of arrays of a fixed size)StructArray(multiple named arrays where each row has one element from each array)UnionArray(every row has a different logical type)DictionaryArray<K>(nested array with encoded values)
Array as a trait object
Array is object safe, and all implementations of Array and can be casted
to &dyn Array, which enables dynamic casting and run-time nesting.
use arrow2::array::{Array, PrimitiveArray}; fn main() { let a = PrimitiveArray::<i32>::from(&[Some(1), None]); let a: &dyn Array = &a; }
Downcast and as_any
Given a trait object array: &dyn Array, we know its physical type via
PhysicalType: array.data_type().to_physical_type(), which we use to downcast the array
to its concrete physical type:
use arrow2::array::{Array, PrimitiveArray}; use arrow2::datatypes::PhysicalType; fn main() { let array = PrimitiveArray::<i32>::from(&[Some(1), None]); let array = &array as &dyn Array; // ... let physical_type: PhysicalType = array.data_type().to_physical_type(); }
There is a one to one relationship between each variant of PhysicalType (an enum) and
an each implementation of Array (a struct):
PhysicalType | Array |
|---|---|
Primitive(_) | PrimitiveArray<_> |
Binary | BinaryArray<i32> |
LargeBinary | BinaryArray<i64> |
Utf8 | Utf8Array<i32> |
LargeUtf8 | Utf8Array<i64> |
List | ListArray<i32> |
LargeList | ListArray<i64> |
FixedSizeBinary | FixedSizeBinaryArray |
FixedSizeList | FixedSizeListArray |
Struct | StructArray |
Union | UnionArray |
Map | MapArray |
Dictionary(_) | DictionaryArray<_> |
where _ represents each of the variants (e.g. PrimitiveType::Int32 <-> i32).
In this context, a common idiom in using Array as a trait object is as follows:
#![allow(unused)] fn main() { use arrow2::datatypes::{PhysicalType, PrimitiveType}; use arrow2::array::{Array, PrimitiveArray}; fn float_operator(array: &dyn Array) -> Result<Box<dyn Array>, String> { match array.data_type().to_physical_type() { PhysicalType::Primitive(PrimitiveType::Float32) => { let array = array.as_any().downcast_ref::<PrimitiveArray<f32>>().unwrap(); // let array = f32-specific operator let array = array.clone(); Ok(Box::new(array)) } PhysicalType::Primitive(PrimitiveType::Float64) => { let array = array.as_any().downcast_ref::<PrimitiveArray<f64>>().unwrap(); // let array = f64-specific operator let array = array.clone(); Ok(Box::new(array)) } _ => Err("This operator is only valid for float point arrays".to_string()), } } }
From Iterator
In the examples above, we've introduced how to create an array from an iterator. These APIs are available for all Arrays, and they are suitable to efficiently create them. In this section we will go a bit more in detail about these operations, and how to make them even more efficient.
This crate's APIs are generally split into two patterns: whether an operation leverages contiguous memory regions or whether it does not.
What this means is that certain operations can be performed irrespectively of whether a value
is "null" or not (e.g. PrimitiveArray<i32> + i32 can be applied to all values
via SIMD and only copy the validity bitmap independently).
When an operation benefits from such arrangement, it is advantageous to use Vec and Into<Buffer>
If not, then use the MutableArray API, such as
MutablePrimitiveArray<T>, MutableUtf8Array<O> or MutableListArray.
We have seen examples where the latter API was used. In the last example of this page you will be introduced to an example of using the former for SIMD.
Into Iterator
We've already seen how to create an array from an iterator. Most arrays also implement
IntoIterator:
use arrow2::array::{Array, Int32Array}; fn main() { let array = Int32Array::from(&[Some(1), None, Some(123)]); for item in array.iter() { if let Some(value) = item { println!("{}", value); } else { println!("NULL"); } } }
Like FromIterator, this crate contains two sets of APIs to iterate over data. Given
an array array: &PrimitiveArray<T>, the following applies:
- If you need to iterate over
Option<&T>, usearray.iter() - If you can operate over the values and validity independently,
use
array.values() -> &Buffer<T>andarray.validity() -> Option<&Bitmap>
Note that case 1 is useful when e.g. you want to perform an operation that depends on both validity and values, while the latter is suitable for SIMD and copies, as they return contiguous memory regions (buffers and bitmaps). We will see below how to leverage these APIs.
This idea holds more generally in this crate's arrays: values() returns something that has
a contiguous in-memory representation, while iter() returns items taking validity into account.
To get an iterator over contiguous values, use array.values().iter().
There is one last API that is worth mentioning, and that is Bitmap::chunks. When performing
bitwise operations, it is often more performant to operate on chunks of bits
instead of single bits. chunks offers a TrustedLen of u64 with the bits
- an extra
u64remainder. We expose two functions,unary(Bitmap, Fn) -> Bitmapandbinary(Bitmap, Bitmap, Fn) -> Bitmapthat use this API to efficiently perform bitmap operations.
Vectorized operations
One of the main advantages of the arrow format and its memory layout is that
it often enables SIMD. For example, an unary operation op on a PrimitiveArray
likely emits SIMD instructions on the following code:
#![allow(unused)] fn main() { use arrow2::buffer::Buffer; use arrow2::{ array::{Array, PrimitiveArray}, types::NativeType, datatypes::DataType, }; pub fn unary<I, F, O>(array: &PrimitiveArray<I>, op: F, data_type: &DataType) -> PrimitiveArray<O> where I: NativeType, O: NativeType, F: Fn(I) -> O, { // apply F over _all_ values let values = array.values().iter().map(|v| op(*v)).collect::<Vec<_>>(); // create the new array, cloning its validity PrimitiveArray::<O>::from_data(data_type.clone(), values.into(), array.validity().cloned()) } }
Some notes:
-
We used
array.values(), as described above: this operation leverages a contiguous memory region. -
We leveraged normal rust iterators for the operation.
-
We used
opon the array's values irrespectively of their validity, and cloned its validity. This approach is suitable for operations whose branching off is more expensive than operating over all values. If the operation is expensive, then usingPrimitiveArray::<O>::from_trusted_len_iteris likely faster.
Clone on write semantics
We support the mutation of arrays in-place via clone-on-write semantics.
Essentially, all data is under an Arc, but it can be taken via Arc::get_mut
and operated in place.
Below is a complete example of how to operate on a Box<dyn Array> without
extra allocations.
{{#include ../examples/cow.rs}}
Compute API
When compiled with the feature compute, this crate offers a wide range of functions
to perform both vertical (e.g. add two arrays) and horizontal
(compute the sum of an array) operations.
The overall design of the compute module is that it offers two APIs:
- statically typed, such as
sum_primitive<T>(&PrimitiveArray<T>) -> Option<T> - dynamically typed, such as
sum(&dyn Array) -> Box<dyn Scalar>
the dynamically typed API usually has a function can_*(&DataType) -> bool denoting whether
the operation is defined for the particular logical type.
Overview of the implemented functionality:
- arithmetics, checked, saturating, etc.
sum,minandmaxunary,binary, etc.comparisoncasttake,filter,concatsort,hash,merge-sortif-then-elsenulliflength(of string)hour,year,month,iso_week(of temporal logical types)regex- (list)
contains
and an example of how to use them:
use arrow2::array::{Array, PrimitiveArray}; use arrow2::compute::arithmetics::basic::*; use arrow2::compute::arithmetics::{add as dyn_add, can_add}; use arrow2::compute::arity::{binary, unary}; use arrow2::datatypes::DataType; fn main() { // say we have two arrays let array0 = PrimitiveArray::<i64>::from(&[Some(1), Some(2), Some(3)]); let array1 = PrimitiveArray::<i64>::from(&[Some(4), None, Some(6)]); // we can add them as follows: let added = add(&array0, &array1); assert_eq!( added, PrimitiveArray::<i64>::from(&[Some(5), None, Some(9)]) ); // subtract: let subtracted = sub(&array0, &array1); assert_eq!( subtracted, PrimitiveArray::<i64>::from(&[Some(-3), None, Some(-3)]) ); // add a scalar: let plus10 = add_scalar(&array0, &10); assert_eq!( plus10, PrimitiveArray::<i64>::from(&[Some(11), Some(12), Some(13)]) ); // a similar API for trait objects: let array0 = &array0 as &dyn Array; let array1 = &array1 as &dyn Array; // check whether the logical types support addition. assert!(can_add(array0.data_type(), array1.data_type())); // add them let added = dyn_add(array0, array1); assert_eq!( PrimitiveArray::<i64>::from(&[Some(5), None, Some(9)]), added.as_ref(), ); // a more exotic implementation: arbitrary binary operations // this is compiled to SIMD when intrinsics exist. let array0 = PrimitiveArray::<i64>::from(&[Some(1), Some(2), Some(3)]); let array1 = PrimitiveArray::<i64>::from(&[Some(4), None, Some(6)]); let op = |x: i64, y: i64| x.pow(2) + y.pow(2); let r = binary(&array0, &array1, DataType::Int64, op); assert_eq!( r, PrimitiveArray::<i64>::from(&[Some(1 + 16), None, Some(9 + 36)]) ); // arbitrary unary operations // this is compiled to SIMD when intrinsics exist. let array0 = PrimitiveArray::<f64>::from(&[Some(4.0), None, Some(6.0)]); let r = unary( &array0, |x| x.cos().powi(2) + x.sin().powi(2), DataType::Float64, ); assert!((r.values()[0] - 1.0).abs() < 0.0001); assert!(r.is_null(1)); assert!((r.values()[2] - 1.0).abs() < 0.0001); // finally, a transformation that changes types: let array0 = PrimitiveArray::<f64>::from(&[Some(4.4), None, Some(4.6)]); let rounded = unary(&array0, |x| x.round() as i64, DataType::Int64); assert_eq!( rounded, PrimitiveArray::<i64>::from(&[Some(4), None, Some(5)]) ); }
Metadata
use arrow2::datatypes::{DataType, Field, Metadata, Schema}; fn main() { // two data types (logical types) let type1_ = DataType::Date32; let type2_ = DataType::Int32; // two fields (columns) let field1 = Field::new("c1", type1_, true); let field2 = Field::new("c2", type2_, true); // which can contain extra metadata: let mut metadata = Metadata::new(); metadata.insert( "Office Space".to_string(), "Deals with real issues in the workplace.".to_string(), ); let field1 = field1.with_metadata(metadata); // a schema (a table) let schema = Schema::from(vec![field1, field2]); assert_eq!(schema.fields.len(), 2); // which can also contain extra metadata: let mut metadata = Metadata::new(); metadata.insert( "Office Space".to_string(), "Deals with real issues in the workplace.".to_string(), ); let schema = schema.with_metadata(metadata); assert_eq!(schema.fields.len(), 2); }
DataType (Logical types)
The Arrow specification contains a set of logical types, an enumeration of the different semantical types defined in Arrow.
In Arrow2, logical types are declared as variants of the enum arrow2::datatypes::DataType.
For example, DataType::Int32 represents a signed integer of 32 bits.
Each DataType has an associated enum PhysicalType (many-to-one) representing the
particular in-memory representation, and is associated to a specific semantics.
For example, both DataType::Date32 and DataType::Int32 have the same PhysicalType
(PhysicalType::Primitive(PrimitiveType::Int32)) but Date32 represents the number of
days since UNIX epoch.
Logical types are metadata: they annotate physical types with extra information about data.
Field (column metadata)
Besides logical types, the arrow format supports other relevant metadata to the format.
An important one is Field broadly corresponding to a column in traditional columnar formats.
A Field is composed by a name (String), a logical type (DataType), whether it is
nullable (bool), and optional metadata.
Schema (table metadata)
The most common use of Field is to declare a arrow2::datatypes::Schema, a sequence of Fields
with optional metadata.
Schema is essentially metadata of a "table": it has a sequence of named columns and their metadata (Fields) with optional metadata.
Foreign Interfaces
One of the hallmarks of the Arrow format is that its in-memory representation has a specification, which allows languages to share data structures via foreign interfaces at zero cost (i.e. via pointers). This is known as the C Data interface.
This crate supports importing from and exporting to all its physical types. The example below demonstrates how to use the API:
use arrow2::array::{Array, PrimitiveArray}; use arrow2::datatypes::Field; use arrow2::error::Result; use arrow2::ffi; fn export(array: Box<dyn Array>) -> (ffi::ArrowArray, ffi::ArrowSchema) { // importing an array requires an associated field so that the consumer knows its datatype. // Thus, we need to export both let field = Field::new("a", array.data_type().clone(), true); ( ffi::export_array_to_c(array), ffi::export_field_to_c(&field), ) } /// # Safety /// `ArrowArray` and `ArrowSchema` must be valid unsafe fn import(array: ffi::ArrowArray, schema: &ffi::ArrowSchema) -> Result<Box<dyn Array>> { let field = ffi::import_field_from_c(schema)?; ffi::import_array_from_c(array, field.data_type) } fn main() -> Result<()> { // let's assume that we have an array: let array = PrimitiveArray::<i32>::from([Some(1), None, Some(123)]).boxed(); // here we export - `array_ffi` and `schema_ffi` are the structs of the C data interface let (array_ffi, schema_ffi) = export(array.clone()); // here we import them. Often the structs are wrapped in a pointer. In that case you // need to read the pointer to the stack. // Safety: we used `export`, which is a valid exporter to the C data interface let new_array = unsafe { import(array_ffi, &schema_ffi)? }; // which is equal to the exported array assert_eq!(array.as_ref(), new_array.as_ref()); Ok(()) }
Extension types
This crate supports Arrows' "extension type", to declare, use, and share custom logical types.
An extension type is just a DataType with a name and some metadata.
In particular, its physical representation is equal to its inner DataType, which implies
that all functionality in this crate works as if it was the inner DataType.
The following example shows how to declare one:
use std::io::{Cursor, Seek, Write}; use arrow2::array::*; use arrow2::chunk::Chunk; use arrow2::datatypes::*; use arrow2::error::Result; use arrow2::io::ipc::read; use arrow2::io::ipc::write; fn main() -> Result<()> { // declare an extension. let extension_type = DataType::Extension("date16".to_string(), Box::new(DataType::UInt16), None); // initialize an array with it. let array = UInt16Array::from_slice([1, 2]).to(extension_type.clone()); // from here on, it works as usual let buffer = Cursor::new(vec![]); // write to IPC let result_buffer = write_ipc(buffer, array)?; // read it back let batch = read_ipc(&result_buffer.into_inner())?; // and verify that the datatype is preserved. let array = &batch.columns()[0]; assert_eq!(array.data_type(), &extension_type); // see https://arrow.apache.org/docs/format/Columnar.html#extension-types // for consuming by other consumers. Ok(()) } fn write_ipc<W: Write + Seek>(writer: W, array: impl Array + 'static) -> Result<W> { let schema = vec![Field::new("a", array.data_type().clone(), false)].into(); let options = write::WriteOptions { compression: None }; let mut writer = write::FileWriter::new(writer, schema, None, options); let batch = Chunk::try_new(vec![Box::new(array) as Box<dyn Array>])?; writer.start()?; writer.write(&batch, None)?; writer.finish()?; Ok(writer.into_inner()) } fn read_ipc(buf: &[u8]) -> Result<Chunk<Box<dyn Array>>> { let mut cursor = Cursor::new(buf); let metadata = read::read_file_metadata(&mut cursor)?; let mut reader = read::FileReader::new(cursor, metadata, None, None); reader.next().unwrap() }
IO
This crate offers optional features that enable interoperability with different formats:
- Arrow (
io_ipc) - CSV (
io_csv) - Parquet (
io_parquet) - JSON and NDJSON (
io_json) - Avro (
io_avroandio_avro_async) - ODBC-compliant databases (
io_odbc)
In this section you can find a guide and examples for each one of them.
CSV reader
When compiled with feature io_csv, you can use this crate to read CSV files.
This crate makes minimal assumptions on how you want to read a CSV, and offers a large degree of customization to it, along with a useful default.
Background
There are two CPU-intensive tasks in reading a CSV file:
- split the CSV file into rows, which includes parsing quotes and delimiters, and is necessary to
seekto a given row. - parse a set of CSV rows (bytes) into a
Arrays.
Parsing bytes into values is more expensive than interpreting lines. As such, it is generally advantageous to have multiple readers of a single file that scan different parts of the file (within IO constraints).
This crate relies on the crate csv to scan and seek CSV files, and your code also needs such a dependency. With that said, arrow2 makes no assumptions as to how to efficiently read the CSV: as a single reader per file or multiple readers.
As an example, the following infers the schema and reads a CSV by re-using the same reader:
use arrow2::array::Array; use arrow2::chunk::Chunk; use arrow2::error::Result; use arrow2::io::csv::read; fn read_path(path: &str, projection: Option<&[usize]>) -> Result<Chunk<Box<dyn Array>>> { // Create a CSV reader. This is typically created on the thread that reads the file and // thus owns the read head. let mut reader = read::ReaderBuilder::new().from_path(path)?; // Infers the fields using the default inferer. The inferer is just a function that maps bytes // to a `DataType`. let (fields, _) = read::infer_schema(&mut reader, None, true, &read::infer)?; // allocate space to read from CSV to. The size of this vec denotes how many rows are read. let mut rows = vec![read::ByteRecord::default(); 100]; // skip 0 (excluding the header) and read up to 100 rows. // this is IO-intensive and performs minimal CPU work. In particular, // no deserialization is performed. let rows_read = read::read_rows(&mut reader, 0, &mut rows)?; let rows = &rows[..rows_read]; // parse the rows into a `Chunk`. This is CPU-intensive, has no IO, // and can be performed on a different thread by passing `rows` through a channel. // `deserialize_column` is a function that maps rows and a column index to an Array read::deserialize_batch(rows, &fields, projection, 0, read::deserialize_column) } fn main() -> Result<()> { use std::env; let args: Vec<String> = env::args().collect(); let file_path = &args[1]; let batch = read_path(file_path, None)?; println!("{:?}", batch); Ok(()) }
Orchestration and parallelization
Because csv's API is synchronous, the functions above represent the "minimal
unit of synchronous work", IO and CPU. Note that rows above are Send,
which implies that it is possible to run parse on a separate thread,
thereby maximizing IO throughput. The example below shows how to do just that:
use crossbeam_channel::unbounded; use std::thread; use std::time::SystemTime; use arrow2::array::Array; use arrow2::chunk::Chunk; use arrow2::{error::Result, io::csv::read}; fn parallel_read(path: &str) -> Result<Vec<Chunk<Box<dyn Array>>>> { let batch_size = 100; let has_header = true; let projection = None; // prepare a channel to send serialized records from threads let (tx, rx) = unbounded(); let mut reader = read::ReaderBuilder::new().from_path(path)?; let (fields, _) = read::infer_schema(&mut reader, Some(batch_size * 10), has_header, &read::infer)?; let fields = Box::new(fields); let start = SystemTime::now(); // spawn a thread to produce `Vec<ByteRecords>` (IO bounded) let child = thread::spawn(move || { let mut line_number = 0; let mut size = 1; while size > 0 { let mut rows = vec![read::ByteRecord::default(); batch_size]; let rows_read = read::read_rows(&mut reader, 0, &mut rows).unwrap(); rows.truncate(rows_read); line_number += rows.len(); size = rows.len(); tx.send((rows, line_number)).unwrap(); } }); let mut children = Vec::new(); // use 3 consumers of to decompress, decode and deserialize. for _ in 0..3 { let rx_consumer = rx.clone(); let consumer_fields = fields.clone(); let child = thread::spawn(move || { let (rows, line_number) = rx_consumer.recv().unwrap(); let start = SystemTime::now(); println!("consumer start - {}", line_number); let batch = read::deserialize_batch( &rows, &consumer_fields, projection, 0, read::deserialize_column, ) .unwrap(); println!( "consumer end - {:?}: {}", start.elapsed().unwrap(), line_number, ); batch }); children.push(child); } child.join().expect("child thread panicked"); let batches = children .into_iter() .map(|x| x.join().unwrap()) .collect::<Vec<_>>(); println!("Finished - {:?}", start.elapsed().unwrap()); Ok(batches) } fn main() -> Result<()> { use std::env; let args: Vec<String> = env::args().collect(); let file_path = &args[1]; let batches = parallel_read(file_path)?; for batch in batches { println!("{}", batch.len()) } Ok(()) }
Async
This crate also supports reading from a CSV asynchronously through the csv-async crate.
The example below demonstrates this:
use tokio::fs::File; use tokio_util::compat::*; use arrow2::error::Result; use arrow2::io::csv::read_async::*; #[tokio::main(flavor = "current_thread")] async fn main() -> Result<()> { use std::env; let args: Vec<String> = env::args().collect(); let file_path = &args[1]; let file = File::open(file_path).await?.compat(); let mut reader = AsyncReaderBuilder::new().create_reader(file); let (fields, _) = infer_schema(&mut reader, None, true, &infer).await?; let mut rows = vec![ByteRecord::default(); 100]; let rows_read = read_rows(&mut reader, 0, &mut rows).await?; let columns = deserialize_batch(&rows[..rows_read], &fields, None, 0, deserialize_column)?; println!("{:?}", columns.arrays()[0]); Ok(()) }
Note that the deserialization should be performed on a separate thread to not block (see also here), which this example does not show.
Customization
In the code above, parser and infer allow for customization: they declare
how rows of bytes should be inferred (into a logical type), and processed (into a value of said type).
They offer good default options, but you can customize the inference and parsing to your own needs.
You can also of course decide to parse everything into memory as Utf8Array and
delay any data transformation.
Write CSV
When compiled with feature io_csv, you can use this crate to write CSV files.
This crate relies on the crate csv to write well-formed CSV files, which your code should also depend on.
The following example writes a batch as a CSV file with the default configuration:
use arrow2::{ array::{Array, Int32Array}, chunk::Chunk, error::Result, io::csv::write, }; fn write_batch<A: AsRef<dyn Array>>(path: &str, columns: &[Chunk<A>]) -> Result<()> { let mut writer = std::fs::File::create(path)?; let options = write::SerializeOptions::default(); write::write_header(&mut writer, &["c1"], &options)?; columns .iter() .try_for_each(|batch| write::write_chunk(&mut writer, batch, &options)) } fn main() -> Result<()> { let array = Int32Array::from(&[ Some(0), Some(1), Some(2), Some(3), Some(4), Some(5), Some(6), ]); let batch = Chunk::try_new(vec![&array as &dyn Array])?; write_batch("example.csv", &[batch]) }
Parallelism
This crate exposes functionality to decouple serialization from writing.
In the example above, the serialization and writing to a file is done synchronously. However, these typically deal with different bounds: serialization is often CPU bounded, while writing is often IO bounded. We can trade-off these through a higher memory usage.
Suppose that we know that we are getting CPU-bounded at serialization, and would like to offload that workload to other threads, at the cost of a higher memory usage. We would achieve this as follows (two batches for simplicity):
use std::io::Write; use std::sync::mpsc; use std::sync::mpsc::{Receiver, Sender}; use std::thread; use arrow2::{ array::{Array, Int32Array}, chunk::Chunk, error::Result, io::csv::write, }; fn parallel_write(path: &str, batches: [Chunk<Box<dyn Array>>; 2]) -> Result<()> { let options = write::SerializeOptions::default(); // write a header let mut writer = std::fs::File::create(path)?; write::write_header(&mut writer, &["c1"], &options)?; // prepare a channel to send serialized records from threads let (tx, rx): (Sender<_>, Receiver<_>) = mpsc::channel(); let mut children = Vec::new(); (0..2).for_each(|id| { // The sender endpoint can be cloned let thread_tx = tx.clone(); let options = options.clone(); let batch = batches[id].clone(); // note: this is cheap let child = thread::spawn(move || { let rows = write::serialize(&batch, &options).unwrap(); thread_tx.send(rows).unwrap(); }); children.push(child); }); for _ in 0..2 { // block: assumes that the order of batches matter. let records = rx.recv().unwrap(); records.iter().try_for_each(|row| writer.write_all(row))? } for child in children { child.join().expect("child thread panicked"); } Ok(()) } fn main() -> Result<()> { let array = Int32Array::from(&[ Some(0), Some(1), Some(2), Some(3), Some(4), Some(5), Some(6), ]); let columns = Chunk::new(vec![array.boxed()]); parallel_write("example.csv", [columns.clone(), columns]) }
Read parquet
When compiled with feature io_parquet, this crate can be used to read parquet files
to arrow.
It makes minimal assumptions on how you to decompose CPU and IO intensive tasks.
First, some notation:
page: part of a column (e.g. similar to a slice of anArray)column chunk: composed of multiple pages (similar to anArray)row group: a group of columns with the same length (similar to aChunk)
Here is how to read a single column chunk from a single row group:
use std::fs::File; use std::time::SystemTime; use arrow2::error::Error; use arrow2::io::parquet::read; fn main() -> Result<(), Error> { // say we have a file use std::env; let args: Vec<String> = env::args().collect(); let file_path = &args[1]; let mut reader = File::open(file_path)?; // we can read its metadata: let metadata = read::read_metadata(&mut reader)?; // and infer a [`Schema`] from the `metadata`. let schema = read::infer_schema(&metadata)?; // we can filter the columns we need (here we select all) let schema = schema.filter(|_index, _field| true); // we can read the statistics of all parquet's row groups (here for the first field) let statistics = read::statistics::deserialize(&schema.fields[0], &metadata.row_groups)?; println!("{:#?}", statistics); // say we found that we only need to read the first two row groups, "0" and "1" let row_groups = metadata .row_groups .into_iter() .enumerate() .filter(|(index, _)| *index == 0 || *index == 1) .map(|(_, row_group)| row_group) .collect(); // we can then read the row groups into chunks let chunks = read::FileReader::new(reader, row_groups, schema, Some(1024 * 8 * 8), None, None); let start = SystemTime::now(); for maybe_chunk in chunks { let chunk = maybe_chunk?; assert!(!chunk.is_empty()); } println!("took: {} ms", start.elapsed().unwrap().as_millis()); Ok(()) }
The example above minimizes memory usage at the expense of mixing IO and CPU tasks on the same thread, which may hurt performance if one of them is a bottleneck.
For single-threaded reading, buffers used to read and decompress pages can be re-used. This create offers an API that encapsulates the above logic:
#![allow(unused)] fn main() { {{#include ../../../examples/parquet_read_record.rs}} }
Parallelism decoupling of CPU from IO
One important aspect of the pages created by the iterator above is that they can cross thread boundaries. Consequently, the thread reading pages from a file (IO-bounded) does not have to be the same thread performing CPU-bounded work (decompressing, decoding, etc.).
The example below assumes that CPU starves the consumption of pages, and that it is advantageous to have a single thread performing all IO-intensive work, by delegating all CPU-intensive tasks to separate threads.
#![allow(unused)] fn main() { {{#include ../../../examples/parquet_read_parallel.rs}} }
This can of course be reversed; in configurations where IO is bounded (e.g. when a network is involved), we can use multiple producers of pages, potentially divided in file readers, and a single consumer that performs all CPU-intensive work.
Apache Arrow <-> Apache Parquet
Arrow and Parquet are two different formats that declare different physical and logical types. When reading Parquet, we must infer to which types we are reading the data to. This inference is based on Parquet's physical, logical and converted types.
When a logical type is defined, we use it as follows:
Parquet | Parquet logical | DataType |
|---|---|---|
| Int32 | Int8 | Int8 |
| Int32 | Int16 | Int16 |
| Int32 | Int32 | Int32 |
| Int32 | UInt8 | UInt8 |
| Int32 | UInt16 | UInt16 |
| Int32 | UInt32 | UInt32 |
| Int32 | Decimal | Decimal |
| Int32 | Date | Date32 |
| Int32 | Time(ms) | Time32(ms) |
| Int64 | Int64 | Int64 |
| Int64 | UInt64 | UInt64 |
| Int64 | Time(us) | Time64(us) |
| Int64 | Time(ns) | Time64(ns) |
| Int64 | Timestamp(_) | Timestamp(_) |
| Int64 | Decimal | Decimal |
| ByteArray | Utf8 | Utf8 |
| ByteArray | JSON | Binary |
| ByteArray | BSON | Binary |
| ByteArray | ENUM | Binary |
| ByteArray | Decimal | Decimal |
| FixedLenByteArray | Decimal | Decimal |
When a logical type is not defined but a converted type is defined, we use the equivalent conversion as above, mutatis mutandis.
When neither is defined, we fall back to the physical representation:
Parquet | DataType |
|---|---|
| Boolean | Boolean |
| Int32 | Int32 |
| Int64 | Int64 |
| Int96 | Timestamp(ns) |
| Float | Float32 |
| Double | Float64 |
| ByteArray | Binary |
| FixedLenByteArray | FixedSizeBinary |
Write to Parquet
When compiled with feature io_parquet, this crate can be used to write parquet files
from arrow.
It makes minimal assumptions on how you to decompose CPU and IO intensive tasks, as well
as an higher-level API to abstract away some of this work into an easy to use API.
First, some notation:
page: part of a column (e.g. similar to a slice of anArray)column chunk: composed of multiple pages (similar to anArray)row group: a group of columns with the same length (similar to aChunkin Arrow)
Single threaded
Here is an example of how to write a single chunk:
use std::fs::File; use arrow2::{ array::{Array, Int32Array}, chunk::Chunk, datatypes::{Field, Schema}, error::Result, io::parquet::write::{ transverse, CompressionOptions, Encoding, FileWriter, RowGroupIterator, Version, WriteOptions, }, }; fn write_chunk(path: &str, schema: Schema, chunk: Chunk<Box<dyn Array>>) -> Result<()> { let options = WriteOptions { write_statistics: true, compression: CompressionOptions::Uncompressed, version: Version::V2, }; let iter = vec![Ok(chunk)]; let encodings = schema .fields .iter() .map(|f| transverse(&f.data_type, |_| Encoding::Plain)) .collect(); let row_groups = RowGroupIterator::try_new(iter.into_iter(), &schema, options, encodings)?; // Create a new empty file let file = File::create(path)?; let mut writer = FileWriter::try_new(file, schema, options)?; for group in row_groups { writer.write(group?)?; } let _size = writer.end(None)?; Ok(()) } fn main() -> Result<()> { let array = Int32Array::from(&[ Some(0), Some(1), Some(2), Some(3), Some(4), Some(5), Some(6), ]); let field = Field::new("c1", array.data_type().clone(), true); let schema = Schema::from(vec![field]); let chunk = Chunk::new(vec![array.boxed()]); write_chunk("test.parquet", schema, chunk) }
Multi-threaded writing
As user of this crate, you will need to decide how you would like to parallelize,
and whether order is important. Below you can find an example where we
use rayon to perform the heavy lift of
encoding and compression.
This operation is embarrassingly parallel
and results in a speed up equal to minimum between the number of cores
and number of columns in the record.
//! Example demonstrating how to write to parquet in parallel. use std::collections::VecDeque; use rayon::prelude::*; use arrow2::{ array::*, chunk::Chunk as AChunk, datatypes::*, error::{Error, Result}, io::parquet::{read::ParquetError, write::*}, }; type Chunk = AChunk<Box<dyn Array>>; struct Bla { columns: VecDeque<CompressedPage>, current: Option<CompressedPage>, } impl Bla { pub fn new(columns: VecDeque<CompressedPage>) -> Self { Self { columns, current: None, } } } impl FallibleStreamingIterator for Bla { type Item = CompressedPage; type Error = Error; fn advance(&mut self) -> Result<()> { self.current = self.columns.pop_front(); Ok(()) } fn get(&self) -> Option<&Self::Item> { self.current.as_ref() } } fn parallel_write(path: &str, schema: Schema, chunks: &[Chunk]) -> Result<()> { // declare the options let options = WriteOptions { write_statistics: true, compression: CompressionOptions::Snappy, version: Version::V2, }; let encoding_map = |data_type: &DataType| { match data_type.to_physical_type() { // remaining is plain _ => Encoding::Plain, } }; // declare encodings let encodings = (&schema.fields) .iter() .map(|f| transverse(&f.data_type, encoding_map)) .collect::<Vec<_>>(); // derive the parquet schema (physical types) from arrow's schema. let parquet_schema = to_parquet_schema(&schema)?; let row_groups = chunks.iter().map(|chunk| { // write batch to pages; parallelized by rayon let columns = chunk .columns() .par_iter() .zip(parquet_schema.fields().to_vec()) .zip(encodings.par_iter()) .flat_map(move |((array, type_), encoding)| { let encoded_columns = array_to_columns(array, type_, options, encoding).unwrap(); encoded_columns .into_iter() .map(|encoded_pages| { let encoded_pages = DynIter::new( encoded_pages .into_iter() .map(|x| x.map_err(|e| ParquetError::General(e.to_string()))), ); encoded_pages .map(|page| { compress(page?, vec![], options.compression).map_err(|x| x.into()) }) .collect::<Result<VecDeque<_>>>() }) .collect::<Vec<_>>() }) .collect::<Result<Vec<VecDeque<CompressedPage>>>>()?; let row_group = DynIter::new( columns .into_iter() .map(|column| Ok(DynStreamingIterator::new(Bla::new(column)))), ); Result::Ok(row_group) }); // Create a new empty file let file = std::io::BufWriter::new(std::fs::File::create(path)?); let mut writer = FileWriter::try_new(file, schema, options)?; // Write the file. for group in row_groups { writer.write(group?)?; } let _size = writer.end(None)?; Ok(()) } fn create_chunk(size: usize) -> Result<Chunk> { let c1: Int32Array = (0..size) .map(|x| if x % 9 == 0 { None } else { Some(x as i32) }) .collect(); let c2: Utf8Array<i64> = (0..size) .map(|x| { if x % 8 == 0 { None } else { Some(x.to_string()) } }) .collect(); Chunk::try_new(vec![ c1.clone().boxed(), c1.clone().boxed(), c1.boxed(), c2.boxed(), ]) } fn main() -> Result<()> { let fields = vec![ Field::new("c1", DataType::Int32, true), Field::new("c2", DataType::Int32, true), Field::new("c3", DataType::Int32, true), Field::new("c4", DataType::LargeUtf8, true), ]; let chunk = create_chunk(100_000_000)?; let start = std::time::SystemTime::now(); parallel_write("example.parquet", fields.into(), &[chunk])?; println!("took: {} ms", start.elapsed().unwrap().as_millis()); Ok(()) }
Read Arrow
When compiled with feature io_ipc, this crate can be used to read Arrow files.
An Arrow file is composed by a header, a footer, and blocks of Arrays.
Reading it generally consists of:
- read metadata, containing the block positions in the file
- seek to each block and read it
The example below shows how to read them into Chunkes:
use std::fs::File; use arrow2::array::Array; use arrow2::chunk::Chunk; use arrow2::datatypes::Schema; use arrow2::error::Result; use arrow2::io::ipc::read; use arrow2::io::print; /// Simplest way: read all record batches from the file. This can be used e.g. for random access. #[allow(clippy::type_complexity)] fn read_chunks(path: &str) -> Result<(Schema, Vec<Chunk<Box<dyn Array>>>)> { let mut file = File::open(path)?; // read the files' metadata. At this point, we can distribute the read whatever we like. let metadata = read::read_file_metadata(&mut file)?; let schema = metadata.schema.clone(); // Simplest way: use the reader, an iterator over batches. let reader = read::FileReader::new(file, metadata, None, None); let chunks = reader.collect::<Result<Vec<_>>>()?; Ok((schema, chunks)) } /// Random access way: read a single record batch from the file. This can be used e.g. for random access. fn read_batch(path: &str) -> Result<(Schema, Chunk<Box<dyn Array>>)> { let mut file = File::open(path)?; // read the files' metadata. At this point, we can distribute the read whatever we like. let metadata = read::read_file_metadata(&mut file)?; let schema = metadata.schema.clone(); // advanced way: read the dictionary let dictionaries = read::read_file_dictionaries(&mut file, &metadata, &mut Default::default())?; // and the chunk let chunk_index = 0; let chunk = read::read_batch( &mut file, &dictionaries, &metadata, None, None, chunk_index, &mut Default::default(), &mut Default::default(), )?; Ok((schema, chunk)) } fn main() -> Result<()> { use std::env; let args: Vec<String> = env::args().collect(); let file_path = &args[1]; let (schema, chunks) = read_chunks(file_path)?; let names = schema.fields.iter().map(|f| &f.name).collect::<Vec<_>>(); println!("{}", print::write(&chunks, &names)); let (schema, chunk) = read_batch(file_path)?; let names = schema.fields.iter().map(|f| &f.name).collect::<Vec<_>>(); println!("{}", print::write(&[chunk], &names)); Ok(()) }
Read Arrow
When compiled with feature io_ipc, this crate can be used to memory map IPC Arrow files
into arrays.
The example below shows how to memory map an IPC Arrow file into Chunkes:
//! Example showing how to memory map an Arrow IPC file into a [`Chunk`]. use std::sync::Arc; use arrow2::error::Result; use arrow2::io::ipc::read; use arrow2::mmap::{mmap_dictionaries_unchecked, mmap_unchecked}; // Arrow2 requires a struct that implements `Clone + AsRef<[u8]>`, which // usually `Arc<Mmap>` supports. Here we mock it #[derive(Clone)] struct Mmap(Vec<u8>); impl AsRef<[u8]> for Mmap { #[inline] fn as_ref(&self) -> &[u8] { self.0.as_ref() } } fn main() -> Result<()> { // given a mmap let mmap = Arc::new(Mmap(vec![])); // read the metadata let metadata = read::read_file_metadata(&mut std::io::Cursor::new(mmap.as_ref()))?; // mmap the dictionaries let dictionaries = unsafe { mmap_dictionaries_unchecked(&metadata, mmap.clone())? }; // and finally mmap a chunk (0 in this case). let chunk = unsafe { mmap_unchecked(&metadata, &dictionaries, mmap, 0) }?; println!("{chunk:?}"); Ok(()) }
Read Arrow streams
When compiled with feature io_ipc, this crate can be used to read Arrow streams.
The example below shows how to read from a stream:
use std::net::TcpStream; use std::thread; use std::time::Duration; use arrow2::array::{Array, Int64Array}; use arrow2::datatypes::DataType; use arrow2::error::Result; use arrow2::io::ipc::read; fn main() -> Result<()> { const ADDRESS: &str = "127.0.0.1:12989"; let mut reader = TcpStream::connect(ADDRESS)?; let metadata = read::read_stream_metadata(&mut reader)?; let mut stream = read::StreamReader::new(&mut reader, metadata); let mut idx = 0; loop { match stream.next() { Some(x) => match x { Ok(read::StreamState::Some(b)) => { idx += 1; println!("batch: {:?}", idx) } Ok(read::StreamState::Waiting) => thread::sleep(Duration::from_millis(2000)), Err(l) => println!("{:?} ({})", l, idx), }, None => break, }; } Ok(()) }
e.g. written by pyarrow:
import pyarrow as pa
from time import sleep
import socket
# Set up the data exchange socket
sk = socket.socket()
sk.bind(("127.0.0.1", 12989))
sk.listen()
data = [
pa.array([1, 2, 3, 4]),
pa.array(["foo", "bar", "baz", None]),
pa.array([True, None, False, True]),
]
batch = pa.record_batch(data, names=["f0", "f1", "f2"])
# Accept incoming connection and stream the data away
connection, address = sk.accept()
dummy_socket_file = connection.makefile("wb")
with pa.RecordBatchStreamWriter(dummy_socket_file, batch.schema) as writer:
for i in range(50):
writer.write_batch(batch)
sleep(1)
via
python main.py &
PRODUCER_PID=$!
sleep 1 # wait for metadata to be available.
cargo run
kill $PRODUCER_PID
Write Arrow
When compiled with feature io_ipc, this crate can be used to write Arrow files.
An Arrow file is composed by a header, a footer, and blocks of RecordBatches.
The example below shows how to write RecordBatches:
use std::fs::File; use arrow2::array::{Array, Int32Array, Utf8Array}; use arrow2::chunk::Chunk; use arrow2::datatypes::{DataType, Field, Schema}; use arrow2::error::Result; use arrow2::io::ipc::write; fn write_batches(path: &str, schema: Schema, chunks: &[Chunk<Box<dyn Array>>]) -> Result<()> { let file = File::create(path)?; let options = write::WriteOptions { compression: None }; let mut writer = write::FileWriter::new(file, schema, None, options); writer.start()?; for chunk in chunks { writer.write(chunk, None)? } writer.finish() } fn main() -> Result<()> { use std::env; let args: Vec<String> = env::args().collect(); let file_path = &args[1]; // create a batch let schema = Schema::from(vec![ Field::new("a", DataType::Int32, false), Field::new("b", DataType::Utf8, false), ]); let a = Int32Array::from_slice(&[1, 2, 3, 4, 5]); let b = Utf8Array::<i32>::from_slice(&["a", "b", "c", "d", "e"]); let chunk = Chunk::try_new(vec![a.boxed(), b.boxed()])?; // write it write_batches(file_path, schema, &[chunk])?; Ok(()) }
Avro read
When compiled with feature io_avro_async, you can use this crate to read Avro files
asynchronously.
use std::sync::Arc; use futures::pin_mut; use futures::StreamExt; use tokio::fs::File; use tokio_util::compat::*; use arrow2::error::Result; use arrow2::io::avro::avro_schema::file::Block; use arrow2::io::avro::avro_schema::read_async::{block_stream, decompress_block, read_metadata}; use arrow2::io::avro::read::{deserialize, infer_schema}; #[tokio::main(flavor = "current_thread")] async fn main() -> Result<()> { use std::env; let args: Vec<String> = env::args().collect(); let file_path = &args[1]; let mut reader = File::open(file_path).await?.compat(); let metadata = read_metadata(&mut reader).await?; let schema = infer_schema(&metadata.record)?; let metadata = Arc::new(metadata); let projection = Arc::new(schema.fields.iter().map(|_| true).collect::<Vec<_>>()); let blocks = block_stream(&mut reader, metadata.marker).await; pin_mut!(blocks); while let Some(mut block) = blocks.next().await.transpose()? { let schema = schema.clone(); let metadata = metadata.clone(); let projection = projection.clone(); // the content here is CPU-bounded. It should run on a dedicated thread pool let handle = tokio::task::spawn_blocking(move || { let mut decompressed = Block::new(0, vec![]); decompress_block(&mut block, &mut decompressed, metadata.compression)?; deserialize( &decompressed, &schema.fields, &metadata.record.fields, &projection, ) }); let chunk = handle.await.unwrap()?; assert!(!chunk.is_empty()); } Ok(()) }
Note how both decompression and deserialization is performed on a separate thread pool to not block (see also here).
Avro write
You can use this crate to write to Apache Avro.
Below is an example, which you can run when this crate is compiled with feature io_avro.
use std::fs::File; use arrow2::{ array::{Array, Int32Array}, datatypes::{Field, Schema}, error::Result, io::avro::avro_schema, io::avro::write, }; fn write_avro<W: std::io::Write>( file: &mut W, arrays: &[&dyn Array], schema: &Schema, compression: Option<avro_schema::file::Compression>, ) -> Result<()> { let record = write::to_record(schema)?; let mut serializers = arrays .iter() .zip(record.fields.iter()) .map(|(array, field)| write::new_serializer(*array, &field.schema)) .collect::<Vec<_>>(); let mut block = avro_schema::file::Block::new(arrays[0].len(), vec![]); write::serialize(&mut serializers, &mut block); let mut compressed_block = avro_schema::file::CompressedBlock::default(); let _was_compressed = avro_schema::write::compress(&mut block, &mut compressed_block, compression)?; avro_schema::write::write_metadata(file, record, compression)?; avro_schema::write::write_block(file, &compressed_block)?; Ok(()) } fn main() -> Result<()> { use std::env; let args: Vec<String> = env::args().collect(); let path = &args[1]; let array = Int32Array::from(&[ Some(0), Some(1), Some(2), Some(3), Some(4), Some(5), Some(6), ]); let field = Field::new("c1", array.data_type().clone(), true); let schema = vec![field].into(); let mut file = File::create(path)?; write_avro(&mut file, &[(&array) as &dyn Array], &schema, None)?; Ok(()) }
JSON read
When compiled with feature io_json, you can use this crate to read NDJSON files:
use std::fs::File; use std::io::{BufReader, Seek}; use arrow2::array::Array; use arrow2::error::Result; use arrow2::io::ndjson::read; use arrow2::io::ndjson::read::FallibleStreamingIterator; fn read_path(path: &str) -> Result<Vec<Box<dyn Array>>> { let batch_size = 1024; // number of rows per array let mut reader = BufReader::new(File::open(path)?); let data_type = read::infer(&mut reader, None)?; reader.rewind()?; let mut reader = read::FileReader::new(reader, vec!["".to_string(); batch_size], None); let mut arrays = vec![]; // `next` is IO-bounded while let Some(rows) = reader.next()? { // `deserialize` is CPU-bounded let array = read::deserialize(rows, data_type.clone())?; arrays.push(array); } Ok(arrays) } fn main() -> Result<()> { // Example of reading a NDJSON file from a path use std::env; let args: Vec<String> = env::args().collect(); let file_path = &args[1]; let arrays = read_path(file_path)?; println!("{:#?}", arrays); Ok(()) }
Note how deserialization can be performed on a separate thread pool to avoid blocking the runtime (see also here).
This crate also supports reading JSON, at the expense of being unable to read the file in chunks.
/// Example of reading a JSON file. use std::fs; use arrow2::array::Array; use arrow2::error::Result; use arrow2::io::json::read; fn read_path(path: &str) -> Result<Box<dyn Array>> { // read the file into memory (IO-bounded) let data = fs::read(path)?; // create a non-owning struct of the data (CPU-bounded) let json = read::json_deserializer::parse(&data)?; // use it to infer an Arrow schema (CPU-bounded) let data_type = read::infer(&json)?; // and deserialize it (CPU-bounded) read::deserialize(&json, data_type) } fn main() -> Result<()> { use std::env; let args: Vec<String> = env::args().collect(); let file_path = &args[1]; let batch = read_path(file_path)?; println!("{:#?}", batch); Ok(()) }
Metadata and inference
This crate uses the following mapping between Arrow's data type and JSON:
JSON | DataType |
|---|---|
| Bool | Boolean |
| Int | Int64 |
| Float | Float64 |
| String | Utf8 |
| List | List |
| Object | Struct |
Write JSON
When compiled with feature io_json, you can use this crate to write JSON.
The following example writes an array to JSON:
use std::fs::File; use arrow2::{ array::{Array, Int32Array}, error::Error, io::json::write, }; fn write_array(path: &str, array: Box<dyn Array>) -> Result<(), Error> { let mut writer = File::create(path)?; let arrays = vec![Ok(array)].into_iter(); // Advancing this iterator serializes the next array to its internal buffer (i.e. CPU-bounded) let blocks = write::Serializer::new(arrays, vec![]); // the operation of writing is IO-bounded. write::write(&mut writer, blocks)?; Ok(()) } fn main() -> Result<(), Error> { use std::env; let args: Vec<String> = env::args().collect(); let file_path = &args[1]; let array = Int32Array::from(&[Some(0), None, Some(2), Some(3), Some(4), Some(5), Some(6)]); write_array(file_path, Box::new(array)) }
Likewise, you can also use it to write to NDJSON:
use std::fs::File; use arrow2::array::{Array, Int32Array}; use arrow2::error::Result; use arrow2::io::ndjson::write; fn write_path(path: &str, array: Box<dyn Array>) -> Result<()> { let writer = File::create(path)?; let serializer = write::Serializer::new(vec![Ok(array)].into_iter(), vec![]); let mut writer = write::FileWriter::new(writer, serializer); writer.by_ref().collect::<Result<()>>() } fn main() -> Result<()> { // Example of reading a NDJSON file from a path use std::env; let args: Vec<String> = env::args().collect(); let file_path = &args[1]; let array = Box::new(Int32Array::from(&[ Some(0), None, Some(2), Some(3), Some(4), Some(5), Some(6), ])); write_path(file_path, array)?; Ok(()) }
ODBC
When compiled with feature io_odbc, this crate can be used to read from, and write to
any ODBC interface:
#![allow(unused)] fn main() { {{#include ../../../examples/odbc.rs}} }